React Native用の軽量な日本語分かち書きモジュールを作りました

React Native用の軽量な日本語分かち書きモジュールを作りました
自分はInkdropというMarkdownノートアプリを作っていて、今新しいモバイル版をReact Nativeで開発しています。そのアプリ用に作成した日本語用分かち書きモジュールを公開したのでご紹介します。
特徴は、ネイティブ実装でかつUIとは別スレッドで処理を行うため、高速でUIがカクつきません。
アプリを作る過程で、日本語のノートの全文検索機能を実現するためにテキストのトークナイズ処理をJavaScriptで実装していました。しかしながら大量のテキストを一度にインデックスしようとすると時間がかかる上に、その間UIが固まってしまう問題がありました。なぜならReact Native製アプリはJavaScriptで組まれていて、シングルスレッドだからです。
そこで、バックグラウンドスレッドで分かち書き処理が行えるネイティブモジュールを作りました。バックグラウンドなのでUIをブロックすることはありませんし、ネイティブ実装なのでパフォーマンスも期待できます。
CFStringTokenizerというクラスがiOSに標準で用意されています。内部ではMeCabが搭載されているという噂です。これを使用しました。
AndroidにはiOSのように標準で形態素解析できるAPIがありません。そこで、辞書いらずの軽量な分かち書きソフトウェアのTinySegmenterを採用しました。こちらはJavaScriptで実装されたものですが、takscapeさんがJavaで書いたものを公開されていたので、使わせていただきました。感謝!
とても簡単です。文字列を指定して tokenize メソッドを呼び出すだけです:
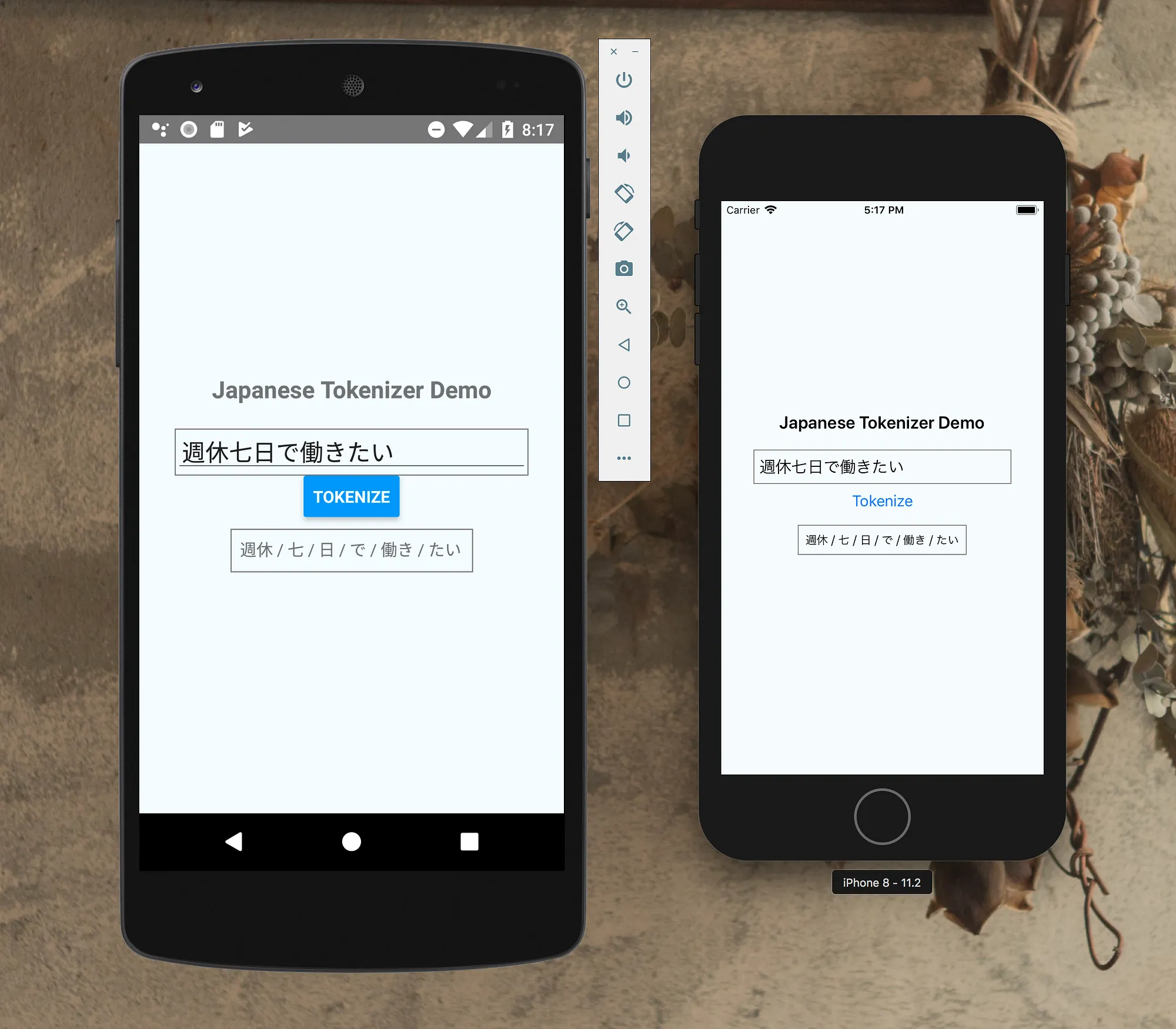
<span id="15e5" class="qs ps io rc b gz rm rn m ro rp">import Tokenizer from 'react-native-japanese-tokenizer'</span><span id="039f" class="qs ps io rc b gz rq rn m ro rp">var text = "週休七日で働きたい"<br></br>const tokens = await Tokenizer.tokenize(text)</span>
tokenize メソッドの戻り値は Promise です。単語単位で分割された文字列の配列が返されます。
iOS/Androidで実装方法が異なるので、分かち書き結果は異なることがあります。しかしながら、全文検索を実現するためならこれで必要充分な精度です。品詞種別などは取得できません。
インストール手順などはREADMEをご参照ください。何か問題がございましたら、Issueを立ててください。
お役に立てば幸いです。:)